Fairness module in dalex¶
We live in a world that is getting more divided each day. In some parts of the world, the differences and inequalities between races, ethnicities, and sometimes sexes are aggravating. The data we use for modeling is in the major part a reflection of the world it derives from. And the world can be biased, so data and therefore model will likely reflect that. The introduction to this topic is well presented in Fairness and machine learning.
We propose a way in which ML engineers can easily check if their model is biased.
Fairness module is still work-in-progres and new features will be added over time.
import dalex as dx
import numpy as np
import plotly
plotly.offline.init_notebook_mode()
dx.__version__
Case study - german credit data¶
To showcase the abilities of the module, we will be using the German Credit dataset to assign risk for each credit-seeker.
This simple task may require using an interpretable decision tree classifier.
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
from sklearn.tree import DecisionTreeClassifier
# credit data
data = dx.datasets.load_german()
# risk is the target
X = data.drop(columns='risk')
y = data.risk
categorical_features = ['sex', 'job', 'housing', 'saving_accounts', "checking_account", 'purpose']
numerical_features = ['age', 'duration', 'credit_amount']
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocessor = ColumnTransformer(transformers=[
('cat', categorical_transformer, categorical_features),
('num', 'passthrough', numerical_features)
])
clf = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', DecisionTreeClassifier(max_depth=7, random_state=123))
])
clf.fit(X, y)
We create an Explainer object to proceed with dalex functionalities.
exp = dx.Explainer(clf, X, y)
exp.model_performance().result
Let's say that performance is satisfying. To check if the model is biased, we will use the fairness module from dalex. Checking if the model is fair should be straightforward. Apart from the dx.Explainer, we will need 2 parameters:
protected- array-like with subgroup values that denote a sensitive attribute (protected variable) like sex, nationality etc. The fairness metrics will be calculated for each of those subgroups and compared.privileged- a string representing one of the subgroups. It should be the one suspected of the most privilege.
# array with values like male_old, female_young, etc.
protected = data.sex + '_' + np.where(data.age < 25, 'young', 'old')
privileged = 'male_old'
Now it is time to check fairness!¶
We use a unified dalex interface to create a fairness explanation object. Use the model_fairness() method:
fobject = exp.model_fairness(protected = protected, privileged=privileged)
The idea here is that ratios between scores of privileged and unprivileged metrics should be close to 1. The closer the more fair the model is. But to relax this criterion a little bit, it can be written more thoughtfully:
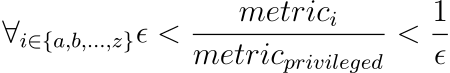
Where the epsilon is a value between 0 and 1, it should be a minimum acceptable value of the ratio. On default, it is 0.8, which adheres to four-fifths rule (80% rule) often looked at in hiring, for example.
fobject.fairness_check(epsilon = 0.8) # default epsilon
This model cannot be called fair! Generally, each metric should be between (epsilon, 1/epsilon). Metrics are calculated for each subgroup, and then their scores are divided by the score of the privileged subgroup. That is why we omit male_old in this method. When at least 2 metrics have scores ratio outside of the epsilon range, the model may be declared unfair. In our case it cannot be decided automatically but the bias is visible and FPR (False Positive Rate) is preety important in case of risk assigning, so let's call our model unfair.
Useful attributes¶
The result attribute is metric_scores where each row is divided by row indexed with privileged (in this case male_old).
# to see all scaled metric values you can run
fobject.result
# or unscaled ones via
fobject.metric_scores
Bias Detection Plots¶
The fairness explanation object includes plots that allow bias visualization from different perspectives:
fairness_checkplotmetric_scoresplot
Fairness Check plot¶
This is a visualization of the fairness_check result.
fobject.plot()
If a bar reaches the red field, it means that for this metric model is exceeding the (epsilon, 1/epsilon) range. In this case the DecisionTreeClassifier has one NaN. In this case appropriate message is given (it can be disabled with verbose=False).
One can also plot metric scores
Metric Scores plot¶
This is a visualization of the metric_scores attribute.
fobject.plot(type = 'metric_scores')
Vertical lines showcase the score of the privileged subgroup. Points closer to the line indicate less bias in the model.
Both plot types are complementary in terms of the metrics. Metric Scores plot is an excellent way to ensure that the interpretation of the Fairness Check plot is on point (small metric values may make the ratios high/low).
Multiple models¶
Supporting multiple model visualization is a key functionality. One can make many models and compare them in terms of the fairness metrics.
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
# create models
numeric_features = ['credit_amount', 'duration', 'age']
numeric_transformer = Pipeline(steps=[
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('cat', categorical_transformer, categorical_features),
('num', numeric_transformer, numeric_features)])
clf_forest = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', RandomForestClassifier(random_state=123, max_depth=5))]).fit(X,y)
clf_logreg = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(random_state=123))]).fit(X,y)
# create Explainer objects
exp_forest = dx.Explainer(clf_forest, X,y, verbose = False)
exp_logreg = dx.Explainer(clf_logreg, X,y, verbose = False)
# create fairness explanations
fobject_forest = exp_forest.model_fairness(protected, privileged)
fobject_logreg = exp_logreg.model_fairness(protected, privileged)
fobject.plot(objects=[fobject_forest, fobject_logreg])
When the plot is missing any bars, a console output will tell the user to check the Metric Scores plot. We can examine why these bars are missing:
fobject.plot(objects=[fobject_forest, fobject_logreg], type = "metric_scores")
Parity loss plots¶
Parity loss plots are other kind of plots that use parity_loss attribute. But what is parity_loss?
# attribute of object
fobject.parity_loss
Parity loss apart from being an attribute is a way that summarizes the bias across subgroups. We needed a function that is symmetrical in terms of division (f(a/b) = f(b/a)). This is why we decided to use following formula:
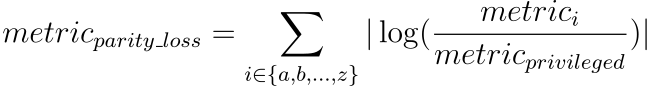
The intuition behind this formula is simple. The bigger the difference in metrics the higher the parity loss will be. It is good entry point for visualization because we have only one value for each metric.
With this knowledge we are now ready for some plots! Note that in all following plots the metrics
can be changed. Just pass metrics = ["TPR", "FPR", ... ]
Radar plot¶
Fairly simple radar plot, it shows each parity loss of metric in form of point on ploar coordinate system.
fobject.plot(objects=[fobject_forest, fobject_logreg], type = "radar")
Judging by the size, the LogisticRegression classifier is the most biased
Heatmap¶
Heatmap is also simple way to check parity loss.
fobject.plot(objects=[fobject_forest, fobject_logreg], type = "heatmap")
When Nans are present the fields will be left without color.
Stacked¶
Stacked plot is a way to look at cumulated parity loss. It stacks each bar on top of each other. The widths of bars depict the amount of bias. The lesser the better.
fobject.plot(objects=[fobject_forest, fobject_logreg], type = "stacked")
Performance and Fairness¶
Sometime it is good idea to look both at performance and fairness metrics. This is where this plot is handy! This plot does not have metrics parameter, but it requires fairness_metric and performance_metric parameters. The dafaults are TPR and accuracy respectively.
fobject.plot(objects=[fobject_forest, fobject_logreg], type = "performance_and_fairness")
Note that y axis is reversed this way the best models are in top right corner.
Ceteris Paribus Cutoff¶
Last but not least is Ceteris Paribus Cutoff plot. It shows us what would happen if we changed cutoff only for one subgroup. It also shows where minimum of summed parity loss of metrics is.
fobject.plot(objects=[fobject_logreg], # for better visibility only one additional model
type = "ceteris_paribus_cutoff",
subgroup="female_young") # necessary argument
To achieve minimal parity loss cutoff for female_young should be set to the values shown by minimums. Please note that manipulating cutoff in this way can be considered unfair because we are artificialy lowering standards for particular subgroup.
Mitigation¶
There are few possible solutions to overcome bias affecting classification models. In dalex, there are 3 mitigation techniques:
resample- returns indices that may be used to pick relevant samples of datareweight- returns sample (case) weights for model trainingroc-pivot- returns theExplainerwith changedy_hat
from dalex.fairness import resample, reweight, roc_pivot
from copy import copy
First, let's prepare models by doing copies of Explainers.
# copying
clf_u = copy(clf)
clf_p = copy(clf)
Resampling¶
# resample
indices_uniform = resample(protected, y, verbose = False)
indices_preferential = resample(protected,
y,
type = 'preferential', # different type
probs = exp.y_hat, # requires probabilities
verbose = False)
clf_u.fit(X.iloc[indices_uniform, :], y[indices_uniform])
clf_p.fit(X.iloc[indices_preferential, :], y[indices_preferential])
Reweight¶
weights = reweight(protected, y, verbose = False)
clf_weighted = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', DecisionTreeClassifier(random_state=123))])
kwargs = {clf_weighted.steps[-1][0] + '__sample_weight': weights}
clf_weighted.fit(X,y, **kwargs)
ROC pivot¶
exp5 = copy(exp)
# roc pivot
exp5 = roc_pivot(exp5, protected, privileged, theta = 0.02, verbose = False)
This function returns an Explainer, but we want to explain the models created before. Next, we make fairness objects.
exp2 = dx.Explainer(clf_weighted, X, y, verbose = False)
exp3 = dx.Explainer(clf_u, X, y, verbose = False)
exp4 = dx.Explainer(clf_p, X, y, verbose = False)
fobject1 = exp.model_fairness(protected, privileged, label='base')
fobject2 = exp2.model_fairness(protected, privileged, label='weighted')
fobject3 = exp3.model_fairness(protected, privileged, label='res_unif')
fobject4 = exp4.model_fairness(protected, privileged, label='res_pref')
fobject5 = exp5.model_fairness(protected, privileged, label='roc')
# plotting
fobject1.plot([fobject2, fobject5, fobject4, fobject3])
We see that the metrics are lower after mitigation. We can also observe this in fairness_check, for example let's investigate roc_pivot.
fobject5.fairness_check()
The only issue is in the FPR metric.
Summary¶
Fairness module in dalex is a unified and accessible way to ensure that the models are fair. In the next versions of the module we plan to add bias mitigation methods. There is a long term plan to add support for individual fairness.
Plots¶
This package uses plotly to render the plots:
- Install extentions to use
plotlyin JupyterLab: Getting Started Troubleshooting - Use
show=Falseparameter inplotmethod to returnplotly Figureobject - It is possible to edit the figures and save them
Resources - https://dalex.drwhy.ai/python¶
Introduction to the
dalexpackage: Titanic: tutorial and examplesKey features explained: FIFA20: explain default vs tuned model with dalex
How to use dalex with: xgboost, tensorflow, h2o (feat. autokeras, catboost, lightgbm)
More explanations: residuals, shap, lime
Introduction to the Fairness module in dalex
Introduction to the Aspect module in dalex
Introduction to Arena: interactive dashboard for model exploration
Code in the form of jupyter notebook
Changelog: NEWS
Theoretical introduction to the plots: Explanatory Model Analysis: Explore, Explain, and Examine Predictive Models